上一篇幅,我们详细介绍了如何安装Prometheus与针对Prometheus、Alertmanager对Dingtalk、Wechat、Email警报做了集成,本篇将会详细的讲解下Prometheus的Alertmanager。
Alertmanager简介
告警能力在Prometheus的架构中被划分成两个独立的部分。如下所示,通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。

在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
在Prometheus中,还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些定义都是通过YAML文件来统一管理的。
Alertmanager作为一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户端程序)的告警信息。Alertmanager可以对这些告警信息进行进一步的处理,比如当接收到大量重复告警时能够消除重复的告警信息,同时对告警信息进行分组并且路由到正确的通知方,Prometheus内置了对邮件,Slack等多种通知方式的支持,同时还支持与Webhook的集成,以支持更多定制化的场景。例如,目前Alertmanager还不支持钉钉,那用户完全可以通过Webhook与钉钉机器人进行集成,从而通过钉钉接收告警信息。同时AlertManager还提供了静默和告警抑制机制来对告警通知行为进行优化。
Alertmanager特性
Alertmanager除了提供基本的告警通知能力以外,还主要提供了如:分组、抑制以及静默等告警特性:
分组
分组机制可以将详细的告警信息合并成一个通知。在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位。
例如,当集群中有数百个正在运行的服务实例,并且为每一个实例设置了告警规则。假如此时发生了网络故障,可能导致大量的服务实例无法连接到数据库,结果就会有数百个告警被发送到Alertmanager。
而作为用户,可能只希望能够在一个通知中中就能查看哪些服务实例收到影响。这时可以按照服务所在集群或者告警名称对告警进行分组,而将这些告警聚合在一起成为一个通知。
告警分组,告警时间,以及告警的接受方式可以通过Alertmanager的配置文件进行配置。
抑制
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
例如,当集群不可访问时触发了一次告警,通过配置Alertmanager可以忽略与该集群有关的其它所有告警。这样可以避免接收到大量与实际问题无关的告警通知。
抑制机制同样通过Alertmanager的配置文件进行设置。
静默
静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。
静默设置需要在Alertmanager的Werb页面上进行设置。
Prometheus告警规则
Prometheus中的告警规则允许你基于PromQL表达式定义告警触发条件,Prometheus后端对这些触发规则进行周期性计算,当满足触发条件后则会触发告警通知。默认情况下,用户可以通过Prometheus的Web界面查看这些告警规则以及告警的触发状态。当Promthues与Alertmanager关联之后,可以将告警发送到外部服务如Alertmanager中并通过Alertmanager可以对这些告警进行进一步的处理。
定义告警规则
一条典型的告警规则如下所示:
groups:
- name: k8stech.net
rules:
- alert: HighErrorRate
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
description: description info在告警规则文件中,我们可以将一组相关的规则设置定义在一个group下。在每一个group中我们可以定义多个告警规则(rule)。一条告警规则主要由以下几部分组成: - alert:告警规则的名称。 - expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。 - for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为* pending。 - labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。 - annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
为了能够让Prometheus能够启用定义的告警规则,我们需要在Prometheus全局配置文件中通过rule_files指定一组告警规则文件的访问路径,Prometheus启动后会自动扫描这些路径下规则文件中定义的内容,并且根据这些规则计算是否向外部发送通知:
为了能够让Prometheus能够启用定义的告警规则,我们需要在Prometheus全局配置文件中通过rule_files指定一组告警规则文件的访问路径,Prometheus启动后会自动扫描这些路径下规则文件中定义的内容,并且根据这些规则计算是否向外部发送通知:
rule_files:
[ - <filepath_glob> ... ]默认情况下Prometheus会每分钟对这些告警规则进行计算,如果用户想定义自己的告警计算周期,则可以通过evaluation_interval来覆盖默认的计算周期:
global:
[ evaluation_interval: <duration> | default = 1m ]模板化
一般来说,在告警规则文件的annotations中使用summary描述告警的概要信息,description用于描述告警的详细信息。同时Alertmanager的UI也会根据这两个标签值,显示告警信息。为了让告警信息具有更好的可读性,Prometheus支持模板化label和annotations的中标签的值。
通过$labels.
# To insert a firing element's label values:
{{ $labels.<labelname> }}
# To insert the numeric expression value of the firing element:
{{ $value }}例如,可以通过模板化优化summary以及description的内容的可读性:
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"查看告警状态
如下所示,用户可以通过Prometheus WEB界面中的Alerts菜单查看当前Prometheus下的所有告警规则,以及其当前所处的活动状态。

同时对于已经pending或者firing的告警,Prometheus也会将它们存储到时间序列ALERTS{}中。
可以通过表达式,查询告警实例:
ALERTS{alertname="<alert name>", alertstate="pending|firing", <additional alert labels>}样本值为1表示当前告警处于活动状态(pending或者firing),当告警从活动状态转换为非活动状态时,样本值则为0。
实例:定义主机监控告警
修改Prometheus配置文件prometheus.yml,添加以下配置:
rule_files:
- /etc/prometheus/rules/*.rules在目录/etc/prometheus/rules/下创建告警文件hoststats-alert.rules内容如下:
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"重启Prometheus后访问Prometheus UI http://127.0.0.1:9090/rules可以查看当前以加载的规则文件。
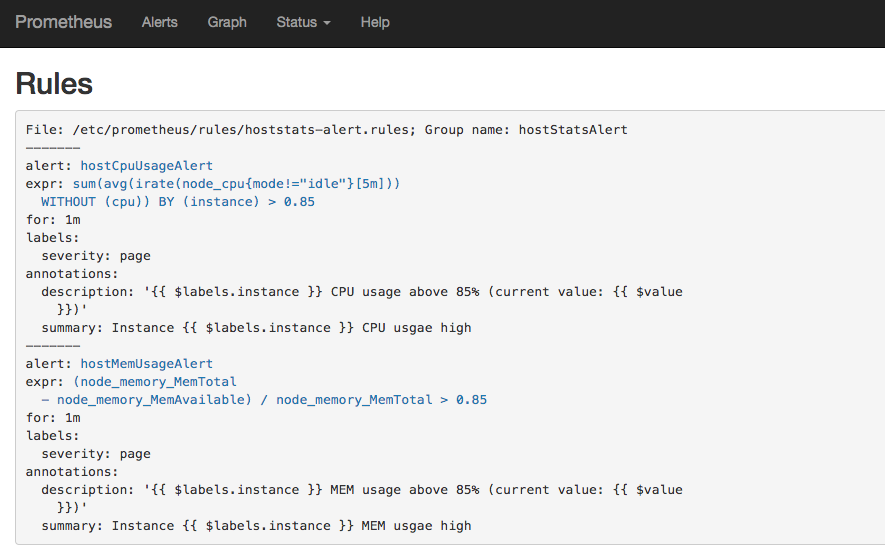
切换到Alerts标签http://127.0.0.1:9090/alerts可以查看当前告警的活动状态。
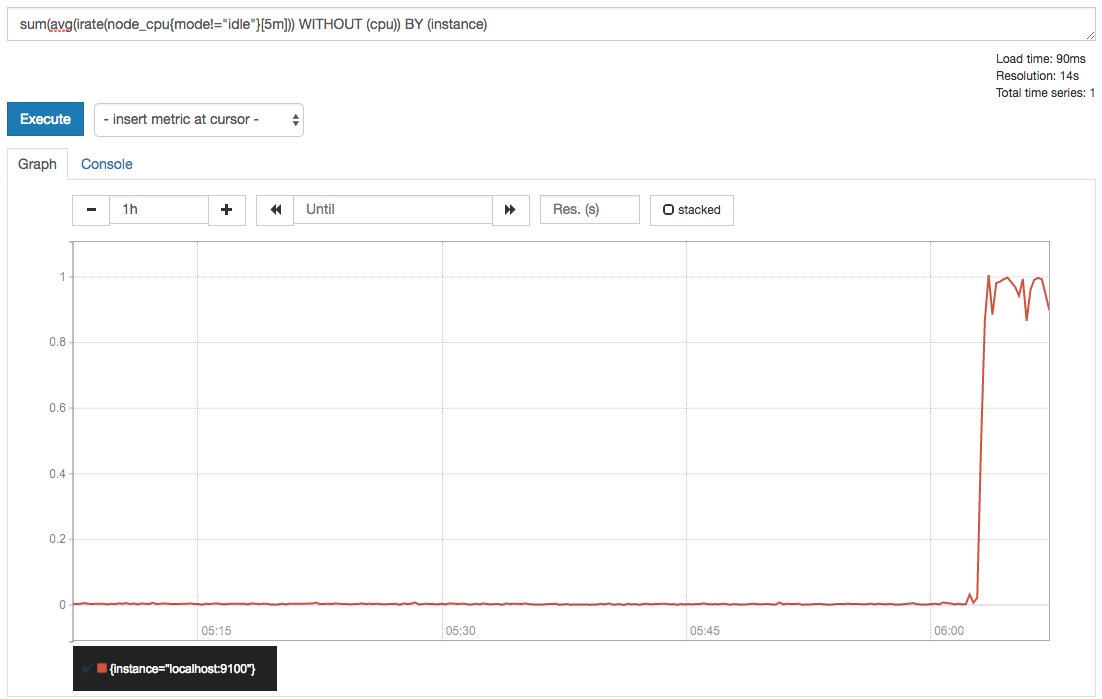
此时,我们可以手动拉高系统的CPU使用率,验证Prometheus的告警流程,在主机上运行以下命令:
cat /dev/zero>/dev/null运行命令后查看CPU使用率情况,如下图所示:
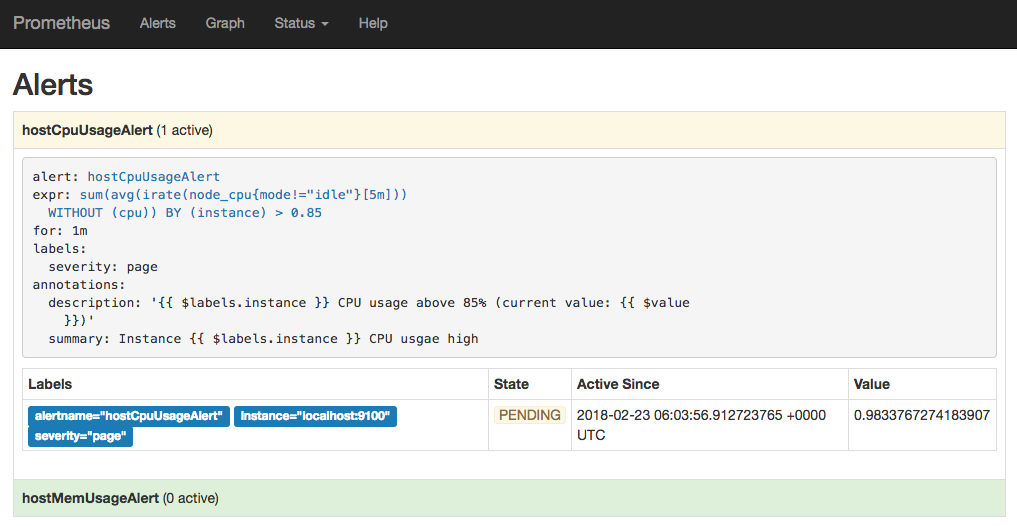
Prometheus首次检测到满足触发条件后,hostCpuUsageAlert显示有一条告警处于活动状态。由于告警规则中设置了1m的等待时间,当前告警状态为PENDING,如下图所示:
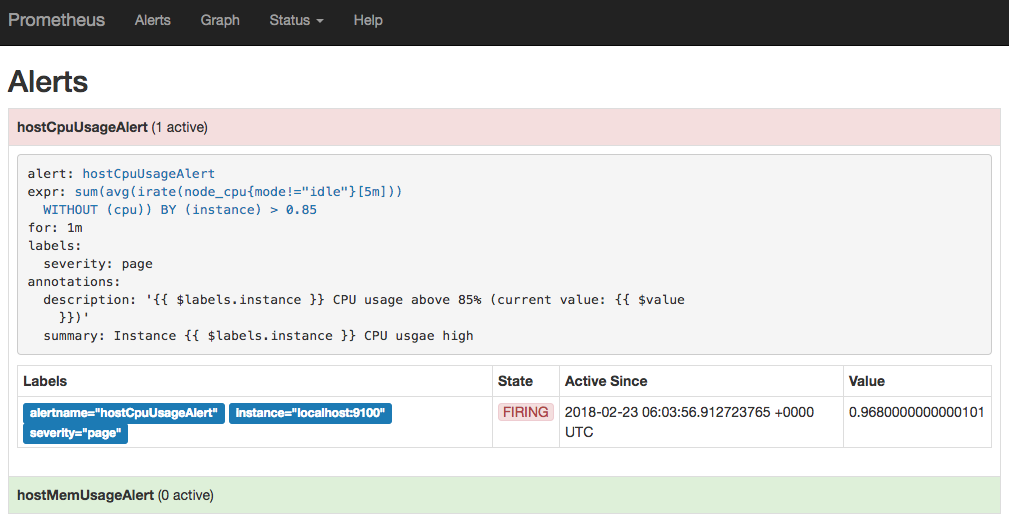
如果1分钟后告警条件持续满足,则会实际触发告警并且告警状态为FIRING,如下图所示:
Alertmanager配置概述
在Alertmanager中通过路由(Route)来定义告警的处理方式。路由是一个基于标签匹配的树状匹配结构。根据接收到告警的标签匹配相应的处理方式。这里将详细介绍路由相关的内容。
Alertmanager主要负责对Prometheus产生的告警进行统一处理,因此在Alertmanager配置中一般会包含以下几个主要部分:
- 全局配置(global):用于定义一些全局的公共参数,如全局的SMTP配置,Slack配置等内容;
- 模板(templates):用于定义告警通知时的模板,如HTML模板,邮件模板等;
- 告警路由(route):根据标签匹配,确定当前告警应该如何处理;
- 接收人(receivers):接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack或者Webhook等,接收人一般配合告警路由使用;
- 抑制规则(inhibit_rules):合理设置抑制规则可以减少垃圾告警的产生
其完整配置格式如下:
global:
resolve_timeout: 5m
# smtp配置
smtp_from: "prom-alert@example.com"
smtp_smarthost: 'email-smtp.us-west-2.amazonaws.com:465'
smtp_auth_username: "user"
smtp_auth_password: "pass"
smtp_require_tls: true
templates:
- '/data/alertmanager/templates/*.tmpl'
route:
receiver: test1
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
group_by: [alertname]
routes:
# ads webhook
- receiver: test1
group_wait: 10s
match:
team: ads
# ops webhook
- receiver: test2
group_wait: 10s
match:
team: operations
receivers:
- name: test1
email_configs:
- to: '9935226@qq.com'
headers: { Subject: "[ads] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8060/dingtalk/ads/send
- name: test2
email_configs:
- to: '9935226@qq.com,9935226@example.com'
send_resolved: true
headers: { Subject: "[ops] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8060/dingtalk/ops/send
# wx config
wechat_configs:
- corp_id: 'wwxxxxxxxxxxxxxx'
api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
send_resolved: true
to_party: '2'
agent_id: '1000002'
api_secret: '1FvHxuGbbG35FYsuW0YyI4czWY/.2'在全局配置中需要注意的是resolve_timeout,该参数定义了当Alertmanager持续多长时间未接收到告警后标记告警状态为resolved(已解决)。该参数的定义可能会影响到告警恢复通知的接收时间,读者可根据自己的实际场景进行定义,其默认值为5分钟。在接下来的部分,我们将以一些实际的例子解释Alertmanager的其它配置内容。
告警模板详解
自定义告警模板 默认情况下Alertmanager使用了系统自带的默认通知模板,模板源码可以从https://github.com/prometheus/alertmanager/blob/master/template/default.tmpl获得。Alertmanager的通知模板基于Go的模板系统。Alertmanager也支持用户定义和使用自己的模板,一般来说有两种方式可以选择。
第一种,基于模板字符串。用户可以直接在Alertmanager的配置文件中使用模板字符串,例如:
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts'
text: 'https://internal.myorg.net/wiki/alerts/{{ .GroupLabels.app }}/{{ .GroupLabels.alertname }}'第二种方式,自定义可复用的模板文件。例如,可以创建自定义模板文件custom-template.tmpl,如下所示:
{{ define "slack.myorg.text" }}https://internal.myorg.net/wiki/alerts/{{ .GroupLabels.app }}/{{ .GroupLabels.alertname }}{{ end}}通过在Alertmanager的全局设置中定义templates配置来指定自定义模板的访问路径:
# Files from which custom notification template definitions are read.
# The last component may use a wildcard matcher, e.g. 'templates/*.tmpl'.
templates:
[ - <filepath> ... ]receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts'
text: '{{ template "slack.myorg.text" . }}'
templates:
- '/etc/alertmanager/templates/myorg.tmpl'基于标签的告警路由
在Alertmanager的配置中会定义一个基于标签匹配规则的告警路由树,以确定在接收到告警后Alertmanager需要如何对其进行处理:
route: <route>其中route中则主要定义了告警的路由匹配规则,以及Alertmanager需要将匹配到的告警发送给哪一个receiver,一个最简单的route定义如下所示:
route:
group_by: ['alertname']
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'如上所示:在Alertmanager配置文件中,我们只定义了一个路由,那就意味着所有由Prometheus产生的告警在发送到Alertmanager之后都会通过名为web.hook的receiver接收。这里的web.hook定义为一个webhook地址。当然实际场景下,告警处理可不是这么简单的一件事情,对于不同级别的告警,我们可能会不完全不同的处理方式,因此在route中,我们还可以定义更多的子Route,这些Route通过标签匹配告警的处理方式,route的完整定义如下:
[ receiver: <string> ]
[ group_by: '[' <labelname>, ... ']' ]
[ continue: <boolean> | default = false ]
match:
[ <labelname>: <labelvalue>, ... ]
match_re:
[ <labelname>: <regex>, ... ]
[ group_wait: <duration> | default = 30s ]
[ group_interval: <duration> | default = 5m ]
[ repeat_interval: <duration> | default = 4h ]
routes:
[ - <route> ... ]路由匹配
每一个告警都会从配置文件中顶级的route进入路由树,需要注意的是顶级的route必须匹配所有告警(即不能有任何的匹配设置match和match_re),每一个路由都可以定义自己的接受人以及匹配规则。默认情况下,告警进入到顶级route后会遍历所有的子节点,直到找到最深的匹配route,并将告警发送到该route定义的receiver中。但如果route中设置continue的值为false,那么告警在匹配到第一个子节点之后就直接停止。如果continue为true,报警则会继续进行后续子节点的匹配。如果当前告警匹配不到任何的子节点,那该告警将会基于当前路由节点的接收器配置方式进行处理。
其中告警的匹配有两种方式可以选择。一种方式基于字符串验证,通过设置match规则判断当前告警中是否存在标签labelname并且其值等于labelvalue。第二种方式则基于正则表达式,通过设置match_re验证当前告警标签的值是否满足正则表达式的内容。
如果警报已经成功发送通知, 如果想设置发送告警通知之前要等待时间,则可以通过repeat_interval参数进行设置。
告警分组
在之前的部分有讲过,Alertmanager可以对告警通知进行分组,将多条告警合并为一个通知。这里我们可以使用group_by来定义分组规则。基于告警中包含的标签,如果满足group_by中定义标签名称,那么这些告警将会合并为一个通知发送给接收器。
有的时候为了能够一次性收集和发送更多的相关信息时,可以通过group_wait参数设置等待时间,如果在等待时间内当前group接收到了新的告警,这些告警将会合并为一个通知向receiver发送。
而group_interval配置,则用于定义相同的Group之间发送告警通知的时间间隔。
例如,当使用Prometheus监控多个集群以及部署在集群中的应用和数据库服务,并且定义以下的告警处理路由规则来对集群中的异常进行通知。
route:
receiver: 'default-receiver'
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
group_by: [cluster, alertname]
routes:
- receiver: 'database-pager'
group_wait: 10s
match_re:
service: mysql|cassandra
- receiver: 'frontend-pager'
group_by: [product, environment]
match:
team: frontend默认情况下所有的告警都会发送给集群管理员default-receiver,因此在Alertmanager的配置文件的根路由中,对告警信息按照集群以及告警的名称对告警进行分组。
如果告警时来源于数据库服务如MySQL或者Cassandra,此时则需要将告警发送给相应的数据库管理员(database-pager)。这里定义了一个单独子路由,如果告警中包含service标签,并且service为MySQL或者Cassandra,则向database-pager发送告警通知,由于这里没有定义group_by等属性,这些属性的配置信息将从上级路由继承,database-pager将会接收到按cluster和alertname进行分组的告警通知。
而某些告警规则来源可能来源于开发团队的定义,这些告警中通过添加标签team来标示这些告警的创建者。在Alertmanager配置文件的告警路由下,定义单独子路由用于处理这一类的告警通知,如果匹配到告警中包含标签team,并且team的值为frontend,Alertmanager将会按照标签product和environment对告警进行分组。此时如果应用出现异常,开发团队就能清楚的知道哪一个环境(environment)中的哪一个应用程序出现了问题,可以快速对应用进行问题定位。
告警接收器Receiver
前上一小节已经讲过,在Alertmanager中路由负责对告警信息进行分组匹配,并将像告警接收器发送通知。告警接收器可以通过以下形式进行配置:
receivers:
- <receiver> ...每一个receiver具有一个全局唯一的名称,并且对应一个或者多个通知方式:
name: <string>
email_configs:
[ - <email_config>, ... ]
hipchat_configs:
[ - <hipchat_config>, ... ]
pagerduty_configs:
[ - <pagerduty_config>, ... ]
pushover_configs:
[ - <pushover_config>, ... ]
slack_configs:
[ - <slack_config>, ... ]
opsgenie_configs:
[ - <opsgenie_config>, ... ]
webhook_configs:
[ - <webhook_config>, ... ]
victorops_configs:
[ - <victorops_config>, ... ]目前官方内置的第三方通知集成包括:邮件、 即时通讯软件(如Slack、Hipchat)、移动应用消息推送(如Pushover)和自动化运维工具(例如:Pagerduty、Opsgenie、Victorops)。Alertmanager的通知方式中还可以支持Webhook,通过这种方式开发者可以实现更多个性化的扩展支持。
告警通知屏蔽
Alertmanager提供了方式可以帮助用户控制告警通知的行为,包括预先定义的抑制机制和临时定义的静默规则。
抑制机制
Alertmanager的抑制机制可以避免当某种问题告警产生之后用户接收到大量由此问题导致的一系列的其它告警通知。例如当集群不可用时,用户可能只希望接收到一条告警,告诉他这时候集群出现了问题,而不是大量的如集群中的应用异常、中间件服务异常的告警通知。
在Alertmanager配置文件中,使用inhibit_rules定义一组告警的抑制规则:
inhibit_rules:
[ - <inhibit_rule> ... ]每一条抑制规则的具体配置如下:
target_match:
[ <labelname>: <labelvalue>, ... ]
target_match_re:
[ <labelname>: <regex>, ... ]
source_match:
[ <labelname>: <labelvalue>, ... ]
source_match_re:
[ <labelname>: <regex>, ... ]
[ equal: '[' <labelname>, ... ']' ]当已经发送的告警通知匹配到target_match和target_match_re规则,当有新的告警规则如果满足source_match或者定义的匹配规则,并且已发送的告警与新产生的告警中equal定义的标签完全相同,则启动抑制机制,新的告警不会发送。
例如,定义如下抑制规则:
- source_match:
alertname: NodeDown
severity: critical
target_match:
severity: critical
equal:
- node例如当集群中的某一个主机节点异常宕机导致告警NodeDown被触发,同时在告警规则中定义了告警级别severity=critical。由于主机异常宕机,该主机上部署的所有服务,中间件会不可用并触发报警。根据抑制规则的定义,如果有新的告警级别为severity=critical,并且告警中标签node的值与NodeDown告警的相同,则说明新的告警是由NodeDown导致的,则启动抑制机制停止向接收器发送通知。
临时静默处理
除了基于抑制机制可以控制告警通知的行为以外,用户或者管理员还可以直接通过Alertmanager的UI临时屏蔽特定的告警通知。通过定义标签的匹配规则(字符串或者正则表达式),如果新的告警通知满足静默规则的设置,则停止向receiver发送通知。
进入Alertmanager UI,点击”New Silence”显示如下内容:
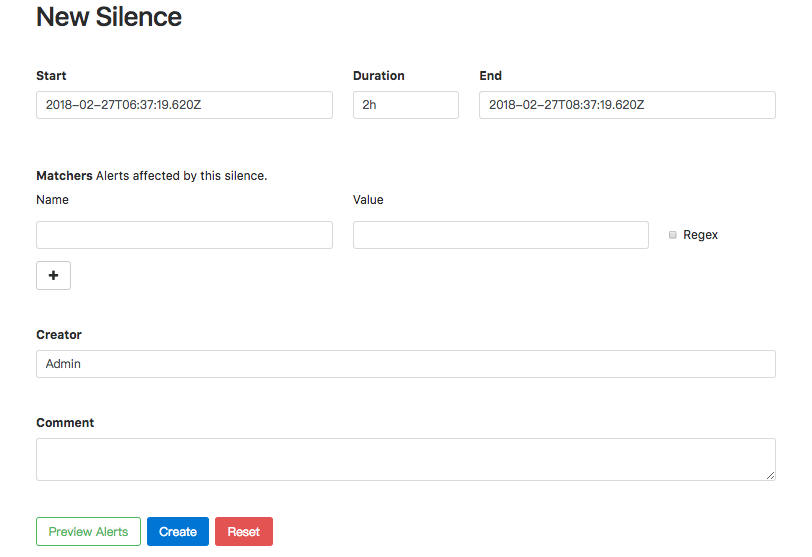
用户可以通过该UI定义新的静默规则的开始时间以及持续时间,通过Matchers部分可以设置多条匹配规则(字符串匹配或者正则匹配)。填写当前静默规则的创建者以及创建原因后,点击”Create”按钮即可。
通过”Preview Alerts”可以查看预览当前匹配规则匹配到的告警信息。静默规则创建成功后,Alertmanager会开始加载该规则并且设置状态为Pending,当规则生效后则进行到Active状态。

当静默规则生效以后,从Alertmanager的Alerts页面下用户将不会看到该规则匹配到的告警信息。

对于已经生效的规则,用户可以通过手动点击”Expire“按钮使当前规则过期。
使用Recoding Rules优化性能
通过PromQL可以实时对Prometheus中采集到的样本数据进行查询,聚合以及其它各种运算操作。而在某些PromQL较为复杂且计算量较大时,直接使用PromQL可能会导致Prometheus响应超时的情况。这时需要一种能够类似于后台批处理的机制能够在后台完成这些复杂运算的计算,对于使用者而言只需要查询这些运算结果即可。Prometheus通过Recoding Rule规则支持这种后台计算的方式,可以实现对复杂查询的性能优化,提高查询效率。
定义Recoding rules
在Prometheus配置文件中,通过rule_files定义recoding rule规则文件的访问路径。
rule_files:
[ - <filepath_glob> ... ]每一个规则文件通过以下格式进行定义:
groups:
[ - <rule_group> ]一个简单的规则文件可能是这个样子的:
groups:
- name: example
rules:
- record: job:http_inprogress_requests:sum
expr: sum(http_inprogress_requests) by (job)rule_group的具体配置项如下所示:
# The name of the group. Must be unique within a file.
name: <string>
# How often rules in the group are evaluated.
[ interval: <duration> | default = global.evaluation_interval ]
rules:
[ - <rule> ... ]与告警规则一致,一个group下可以包含多条规则rule。
# The name of the time series to output to. Must be a valid metric name.
record: <string>
# The PromQL expression to evaluate. Every evaluation cycle this is
# evaluated at the current time, and the result recorded as a new set of
# time series with the metric name as given by 'record'.
expr: <string>
# Labels to add or overwrite before storing the result.
labels:
[ <labelname>: <labelvalue> ]根据规则中的定义,Prometheus会在后台完成expr中定义的PromQL表达式计算,并且将计算结果保存到新的时间序列record中。同时还可以通过labels为这些样本添加额外的标签。
这些规则文件的计算频率与告警规则计算频率一致,都通过global.evaluation_interval定义:
global:
[ evaluation_interval: <duration> | default = 1m ]结语
当故障发生时,实时获取到异常结果与通知是多数用户使用监控系统的主要目的,Prometheus提供的告警以及告警处理能力,通过内置的警报中心,可以友好的帮助我们实现快速警报通知,并且对扩展支持友好,使得用户可以基于Prometheus监控系统的告警处理模式实现更多的定制化功能。
为了方便大家, 提供一个收集各个exporter以及相关的警报规则站点: https://www.prometheus.wang/di-wu-zhang-jing-bao/chang-yong-cha-xun-alert-rules
下一篇幅,我们讲讲Prometheus的动态发现与配置中心,对于所有文章,自始如终的以内容为王,不浪费大家的时间,能让大家看到的文章对自己有所提升与帮助,谢谢。
微信公众号
扫描下面的二维码关注我的微信公众号,在微信公众帐号中回复'群'即可加入到我的"kubernetes技术栈"讨论群里面共同学习。

「真诚赞赏,手有余香」
请我喝杯咖啡?
使用微信扫描二维码完成支付

